Python Architecture Essentials: Building Scalable and Clean Application for Juniors
Structuring a project with SOLID, KISS, DRY, and clean code principles, along with efficient design patterns. In simple words with real examples.
When it comes to creating scalable and maintainable Python applications, understanding essential concepts such as clean code principles, architectural patterns, and SOLID design practices is crucial. By exploring these principles, beginners will gain insights into building robust, flexible, and easily testable applications, ensuring that their codebase remains clear and maintainable as their projects grow.
Some Clean Code Theory
Before diving into architecture, I would like to answer a few frequently asked questions:
What are the benefits of specifying types in Python?
What are the reasons for splitting an app into layers?
What are the advantages of using OOP?
What are the drawbacks of using global variables or singletons?
Feel free to skip the theory sections if you already know the answers and jump directly to the "Building the App" section.
Always Annotate Types
Annotating all types in Python significantly enhances your code by increasing its clarity, robustness, and maintainability:
Type Safety: Type annotations help catch type mismatches early, reducing bugs and ensuring your code behaves as expected.
Self-documenting Code: Type hints increase the readability of your code and act as built-in documentation, clarifying the expected input and output data types of functions.
Improved Code Quality: Employing type hints encourages better design and architecture, promoting thoughtful planning and implementation of data structures and interfaces.
Enhanced Tool Support: Tools like mypy utilize type annotations for static type checking, identifying potential errors before runtime, thus enhancing the development process.
Support from Modern Libraries: Libraries such as FastAPI and Pydantic leverage type annotations to provide functionalities like automatic data validation, schema generation, and comprehensive API documentation.
Advantages of Typed Dataclasses Over Simple Data Structures: Typed dataclasses improve readability, structured data handling, and type safety compared to dicts and tuples. They use attributes instead of string keys, which minimizes errors due to typos and improves code autocompletion. Dataclasses also provide clear definitions of data structures, support default values, and simplify code maintenance and debugging.
Separation of concerns
- Each layer focuses on a specific aspect, which simplifies development, debugging and maintenance.
Reusability
- Layers can be reused in different parts of the application or in other projects. Code duplication is eliminated.
Scalability
- Allows different layers to scale independently of each other depending on needs.
Serviceability
- Simplifies maintenance by localizing common functions in separate layers.
Improved collaboration
- Teams can work on different layers independently.
Flexibility and adaptability
- Changes in technology or design can be implemented in specific layers. Only the affected layers need to be adapted, the others remain unaffected.
Testability
- Each layer can be tested independently, simplifying unit testing and debugging.
Adopting a layered architecture offers significant advantages in development speed, operational management, and long-term maintenance, making systems more robust, manageable, and adaptable to change.
Procedural vs OOP
Using Object-Oriented Programming (OOP) and Dependency Injection (DI) can significantly enhance code quality and maintainability compared to a procedural approach with global variables and functions. Here's a simple comparison that demonstrates these advantages:
Procedural Approach: Global Variables and Functions
# Global configuration
database_config = {
'host': 'localhost',
'port': 3306,
'user': 'user',
'password': 'pass'
}
def connect_to_database():
print(f"Connecting to database on {database_config['host']}...")
# Assume connection is made
return "database_connection"
def fetch_user(database_connection, user_id):
print(f"Fetching user {user_id} using {database_connection}")
# Fetch user logic
return {'id': user_id, 'name': 'John Doe'}
# Usage
db_connection = connect_to_database()
user = fetch_user(db_connection, 1)
Code Duplication:
database_configmust be passed around or accessed globally in multiple functions.Testing Difficulty: Mocking the database connection or configuration involves manipulating global state, which is error-prone.
Tight Coupling: Functions directly depend on global state and specific implementations.
OOP + DI Approach
from typing import Dict, Optional
from abc import ABC, abstractmethod
class DatabaseConnection(ABC):
@abstractmethod
def connect(self):
pass
@abstractmethod
def fetch_user(self, user_id: int) -> Dict:
pass
class MySQLConnection(DatabaseConnection):
def __init__(self, config: Dict[str, str]):
self.config = config
def connect(self):
print(f"Connecting to MySQL database on {self.config['host']}...")
# Assume connection is made
def fetch_user(self, user_id: int) -> Dict:
print(f"Fetching user {user_id} from MySQL")
return {'id': user_id, 'name': 'John Doe'}
class UserService:
def __init__(self, db_connection: DatabaseConnection):
self.db_connection = db_connection
def get_user(self, user_id: int) -> Dict:
return self.db_connection.fetch_user(user_id)
# Configuration and DI
config = {
'host': 'localhost',
'port': 3306,
'user': 'user',
'password': 'pass'
}
db = MySQLConnection(config)
db.connect()
user_service = UserService(db)
user = user_service.get_user(1)
Reduced Code Duplication: The database configuration is encapsulated within the connection object; no need to pass it around.
DI Possibilities: Easily switch out
MySQLConnectionwith another database connection class without changingUserServicecode.Encapsulation and Abstraction: Implementation details of how users are fetched or how the database is connected are hidden away.
Ease of Mocking and Testing:
UserServicecan be easily tested by injecting a mock or stub ofDatabaseConnection.Object Lifetime Management: The lifecycle of database connections can be managed more granularly (e.g., using context managers).
Use of OOP Principles: Demonstrates inheritance (abstract base class), polymorphism (implementing abstract methods), and protocols (interfaces defined by
DatabaseConnection).
By structuring the application using OOP and DI, the code becomes more modular, easier to test, and flexible to changes, such as swapping out dependencies or changing configurations.
Global Constants vs Injected Parameters
When developing software, the choice between using global constants and employing dependency injection (DI) can significantly impact the flexibility, maintainability, and scalability of applications. This analysis delves into the drawbacks of global constants and contrasts them with the advantages provided by dependency injection.
Global Constants
Fixed Configuration: Global constants are static and cannot dynamically adapt to different environments or requirements without modifying the codebase. This rigidity limits their utility across diverse operational scenarios.
Limited Testing Scope: Testing becomes challenging with global constants as they are not easily overridden. Developers might need to alter the global state or employ complex workarounds to accommodate different test scenarios, thereby increasing the risk of errors.
Reduced Modularity: Relying on global constants decreases modularity since components become dependent on specific values being set globally. This dependence reduces the reusability of components across different projects or contexts.
Tight Coupling: Global constants integrate specific behaviors and configurations directly into the codebase, making it difficult to adapt or evolve the application without extensive modifications.
Hidden Dependencies: Similar to global variables, global constants obscure the dependencies within an application. It becomes unclear which parts of the system rely on these constants, complicating both the understanding and the maintenance of the code.
Namespace Pollution and Scalability Challenges: Global constants can clutter the namespace and complicate the scaling of applications. They promote a design that isn't modular, hindering efficient distribution across different processes.
Maintenance and Refactoring Difficulties: Over time, the use of global constants can lead to maintenance challenges. Refactoring such a codebase is risky as changes to the constants might inadvertently affect disparate parts of the application.
Module-Level State Duplication: In Python, module-level code might be executed multiple times if imports occur under different paths (e.g., absolute vs. relative). This can lead to duplication of global instances and hard-to-track maintenance bugs, further complicating the application’s stability and predictability.
Injected Parameters
Dynamic Flexibility and Configurability: Dependency injection allows for the dynamic configuration of components, making applications adaptable to varying conditions without needing code changes.
Enhanced Testability: DI improves testability by enabling the injection of mock objects or alternative configurations during tests, effectively isolating components from external dependencies and ensuring more reliable test outcomes.
Increased Modularity and Reusability: Components become more modular and reusable as they are designed to operate with any injected parameters that conform to expected interfaces. This separation of concerns enhances the portability of components across various parts of an application or even different projects.
Loose Coupling: Injected parameters promote loose coupling by decoupling the system’s logic from its configuration. This approach facilitates easier updates and changes to the application.
Explicit Dependency Declaration: With DI, components clearly declare their dependencies, typically through constructor parameters or setters. This clarity makes the system easier to understand, maintain, and extend.
Scalability and Complexity Management: As applications grow, DI helps manage complexity by localizing concerns and separating configuration from usage, aiding in the effective scaling and maintenance of large systems.
Building the App
You can find all examples and more details with comments at the repo
Starting a new Project
Just a short check-list:
1. Project and Dependency Management with Poetry
Poetry shines not only as a project creation tool but also excels in managing dependencies and virtual environments. Start by setting up your project structure using the following command:
poetry new python-app-architecture-demo
This command crafts a well-organized directory structure: separate folders for Python code and tests, with a root directory for meta-information like pyproject.toml, lock files, and Git configurations.
2. Version Control with Git
Initialize Git in your project directory:
git init
Add a .gitignore file to exclude unnecessary files from your repository. Use the standard Python .gitignore provided by GitHub, and append any specific exclusions like .DS_Store for macOS:
wget -O .gitignore https://raw.githubusercontent.com/github/gitignore/main/Python.gitignore
echo .DS_Store >> .gitignore
3. Manage Dependencies
Install your project’s dependencies using Poetry:
poetry add fastapi pytest aiogram
You can install all dependencies later using:
poetry install
Refer to the official documentation of each library if you need more specific instructions.
4. Configuration Files
Create a config.py file to centralize your application settings—a common and effective approach.
Also, manage environment variables effectively:
touch .env example.env
.env contains sensitive data and should be git-ignored, while example.env holds placeholder or default values and is checked into the repository.
5. Application Entry Point
Define the entry point of your application in main.py:
python_app_architecture/main.py:
def run():
print('Hello, World!')
if __name__ == '__main__': # to avoid run on import
run()
Make your project usable as a library and allow programmatic access by importing the run function in the __init__.py:
python_app_architecture/init.py
from .main import run
Enable direct project execution with Poetry by adding a shortcut in __main__.py. This allows you to use the command poetry run python python_app_architecture instead of the longer poetry run python python_app_architecture/main.py.
python_app_architecture/main.py:
from .main import run
run()
Defining Directories and Layers
Disclaimer:
Of course, every application is different and their architecture will differ depending on the goals and objectives. I'm not saying that this is the only correct option, but I think that this one is fairly average and suitable for a big part of projects. Try to focus on main approaches and ideas rather than specific examples.
Now, let's setup directories for different layers of the application.
Typically, it's wise to version your API (e.g., by creating subdirectories like api/v1), but we'll keep things simple for now and omit this step.
.
├── python_app_architecture_demo
│ ├── coordinator.py
│ ├── entities
│ ├── general
│ ├── mappers
│ ├── providers
│ ├── repository
│ │ └── models
│ └── services
│ ├── api_service
│ │ └── api
│ │ ├── dependencies
│ │ ├── endpoints
│ │ └── schemas
│ └── telegram_service
└── tests
The App
Entities — App-wide data structures. Purely carriers of data with no embedded logic.
General — The utility belt! A consolidated hub for shared utilities, helpers, and library facades.
Mappers — Specialists in data translation, converting between data forms like database models to entities or between different data formats. It's good practice to encapsulate mappers to its usage boundary instead of making them global. For example, models-entities mapper may be part of the repository module. Another example: schemas-entities mapper must stay inside api service and be its private tool.
Providers — The backbone of core business logic. Providers implement the main logic of the application but remain agnostic of the interface details, ensuring their operations are abstract and isolated.
Repository — The librarians. Custodians of data access, abstracting the complexities of data source interactions through models, thus isolating database operations from the broader app.
- Models — Definitions of local data structures interacting with the database, distinct and isolated from Entities.
Services — Each service acts as a (almost) standalone sub-application, orchestrating its specific domain of business logic while delegating foundational tasks to providers. This configuration ensures centralized and uniform application-wide logic
API Service — Manages external communications via HTTP/S, structured around a FastAPI framework.
Dependencies — Essential tools and helpers required by various parts of your API, integrated via FastAPI’s DI system.
Endpoints — Routes that publicly expose your business logic via HTTP.
Schemas — Data structure definitions for API inputs and outputs, confined to their service layer to maintain encapsulation.
Telegram Service — Operates similarly to the API Service, providing functionality via Telegram without replicating the core business logic. This is achieved by calling the same providers that API Service uses, ensuring consistency and reducing code redundancy.
Tests — Dedicated solely to testing, this directory contains all test code, maintaining a clear separation from application logic.
The connection between layers will look something like this:
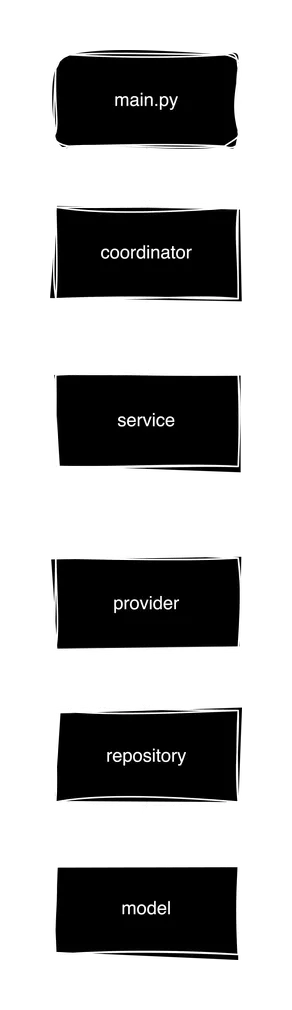
Note that entities are not active components, but only data structures that are passed between layers:
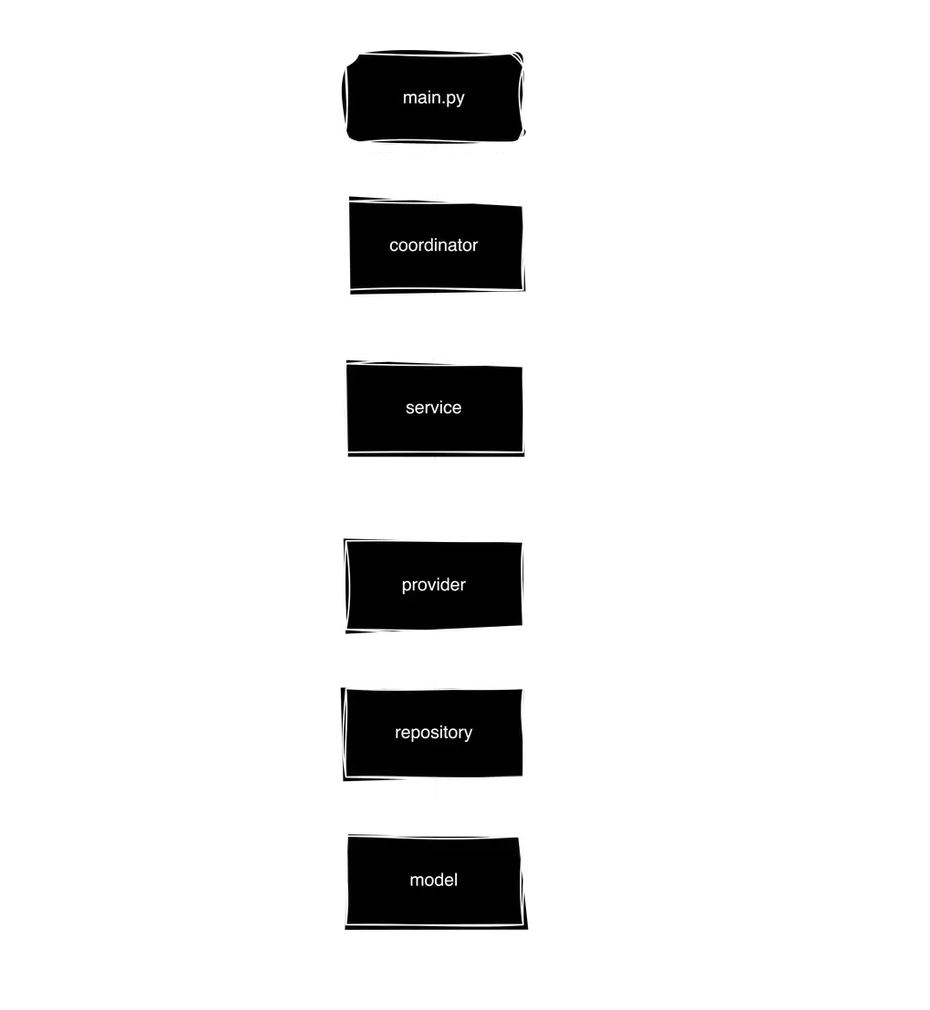
Keep in mind that layers are not directly connected, but only depend on abstractions. Implementations are passed using dependency injection:
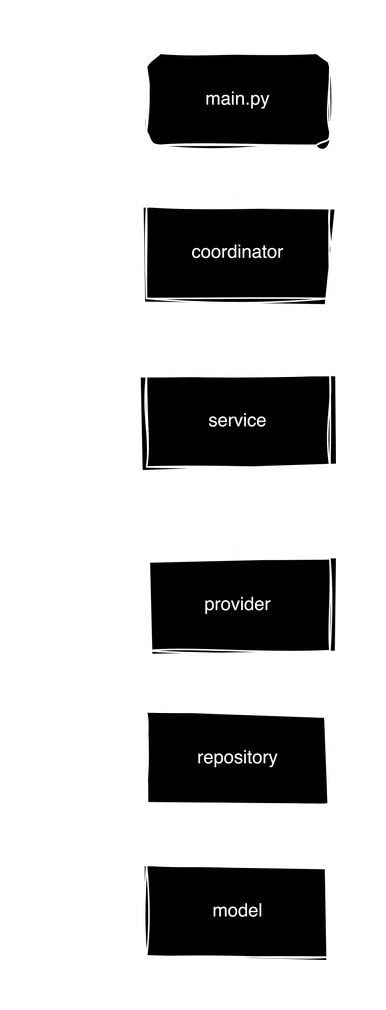
This flexible structure allows you to easily add functionality, for example, change the database, create a service, or connect a new interface without extra changes or code duplication, because logic of each module is located on its own layer:
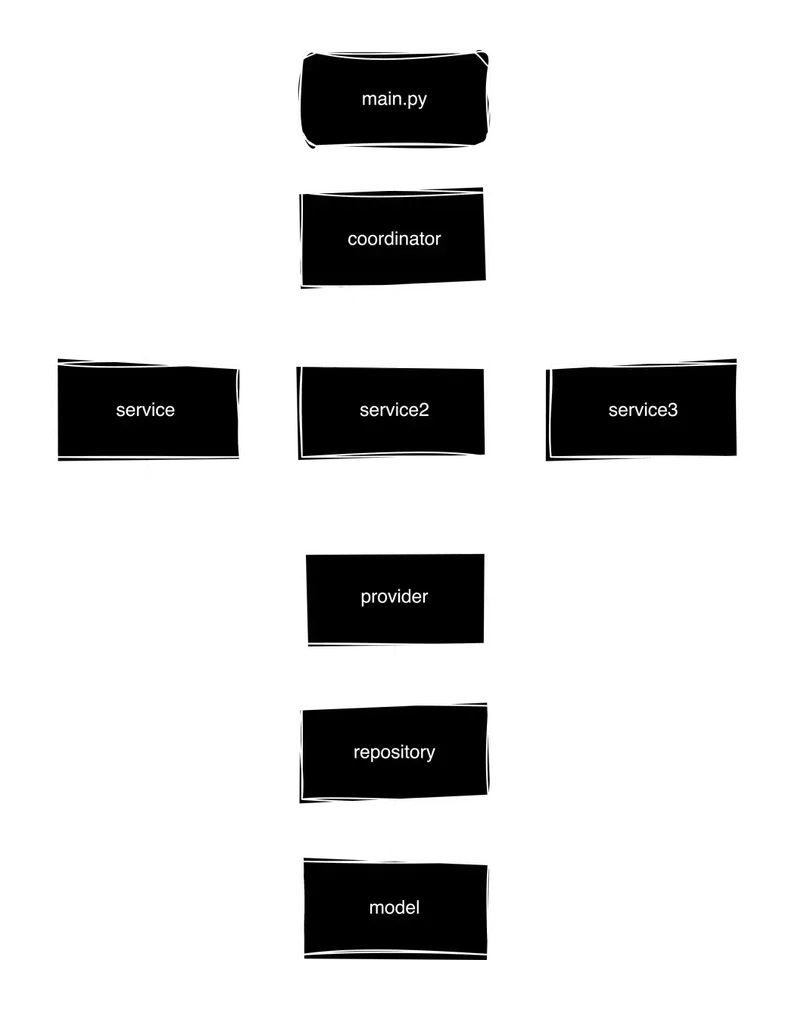
At the same time, all logic of a separate service is encapsulated within it:
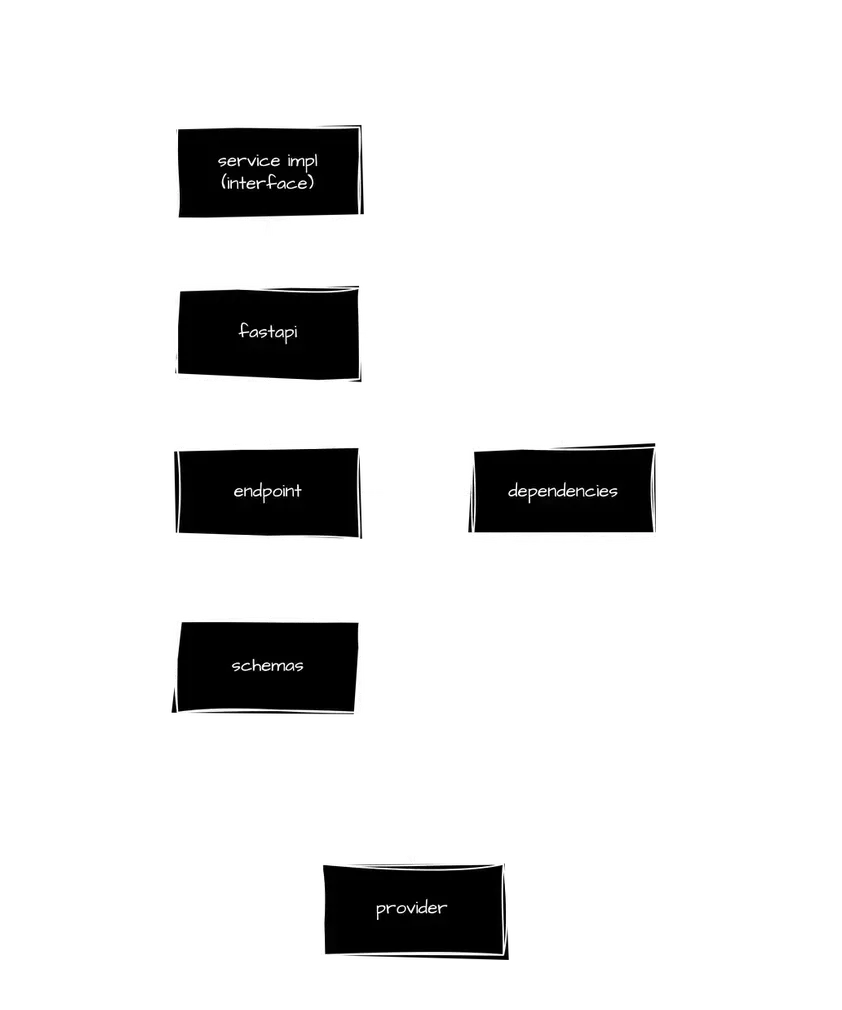
Exploring the Code
Endpoint
Let's start from the endpoint:
# api_service/api/endpoints/user.py
from typing import Annotated
from fastapi import APIRouter, Depends, HTTPException, status
from entities.user import UserCreate
from ..dependencies.providers import (
user_provider, # 1
UserProvider # 2
)
router = APIRouter()
@router.post("/register")
async def register(
user: UserCreate, # 3
provider: Annotated[UserProvider, Depends(user_provider)] # 4
):
provider.create_user(user) # 5
return {"message": "User created!"}
Importing dependency injection helper function (we will look at it in a minute)
Importing UserProvider protocol for type annotation
Endpoint requires the request's body to have
UserCreatescheme in json formatThe
providerparameter in theregisterfunction is an instance of implementation ofUserProvider, injected by FastAPI using theDependsmechanism.The
create_usermethod of theUserProvideris called with the parsed user data. This demonstrates a clear separation of concerns, where the API layer delegates business logic to the provider layer, adhering to the principle that interface layers should not contain business logic.
UserProvider
Now, let's see the business logic:
# providers/user_provider.py
from typing import Protocol, runtime_checkable, Callable
from typing_extensions import runtime_checkable
from repository import UserRepository
from providers.mail_provider import MailProvider
from entities.user import UserCreate
@runtime_checkable
class UserProvider(Protocol): # 1
def create_user(self, user: UserCreate): ...
@runtime_checkable
class UserProviderOutput(Protocol): # 2
def user_provider_created_user(self, provider: UserProvider, user: UserCreate): ...
class UserProviderImpl: # 3
def __init__(self,
repository: UserRepository, # 4
mail_provider: MailProvider, # 4
output: UserProviderOutput | None, # 5
on_user_created: Callable[UserCreate], None] | None # 6
):
self.repository = repository
self.mail_provider = mail_provider
self.output = output
self.on_user_created = on_user_created
# Implementation
def create_user(self, user: UserCreate): # 7
self.repository.add_user(user) # 8
self.mail_provider.send_mail(user.email, f"Welcome, {user.name}!") # 9
if output := self.output: # unwraping the optional
output.user_provider_created_user(self, user) # 10
# 11
if on_user_created := self.on_user_created:
on_user_created(user)
Defining the Interface:
UserProvideris a protocol that specifies the methodcreate_user, which any class adhering to this protocol must implement. It serves as a formal contract for user creation functionality.Observer Protocol:
UserProviderOutputserves as an observer (or delegate) that is notified when a user is created. This protocol enables loose coupling and enhances the event-driven architecture of the application.Protocol Implementation:
UserProviderImplimplements the user creation logic but does not need to explicitly declare its adherence toUserProviderdue to Python's dynamic nature and the use of duck typing.Core Dependencies: The constructor accepts
UserRepositoryandMailProvider—both defined as protocols—as parameters. By relying solely on these protocols, theUserProviderImplremains decoupled from specific implementations, illustrating the principles of Dependency Injection where the provider is agnostic of the underlying details, interfacing only through defined contracts.Optional Output Delegate: The constructor accepts an optional
UserProviderOutputinstance, which, if provided, will be notified upon the completion of user creation.Callback Function: As an alternative to the output delegate, a callable
on_user_createdcan be passed to handle additional actions post-user creation, providing flexibility in response to events.Central Business Logic: The
create_usermethod encapsulates the main business logic for adding a user, demonstrating separation from API handling.Repository Interaction: Utilizes the
UserRepositoryto abstract the database operations (e.g., adding a user), ensuring the provider does not directly manipulate the database.Extended Business Logic: Involves sending an email through
MailProvider, illustrating that the provider's responsibilities can extend beyond simple CRUD operations.Event Notification: If an output delegate is provided, it notifies this delegate about the user creation event, leveraging the observer pattern for enhanced interactivity and modular reactions to events.
Callback Execution: Optionally executes a callback function, providing a straightforward method to extend functionality without complex class hierarchies or dependencies.
FastAPI Dependencies
Ok, but how to instantiate the provider and inject it? Let's take a look at the injection code, powered by FastAPI's DI engine:
# services/api_service/api/dependencies/providers.py
from typing import Annotated
from fastapi import Request, Depends
from repository import UserRepository
from providers.user_provider import UserProvider, UserProviderImpl
from providers.mail_provider import MailProvider
from coordinator import Coordinator
from .database import get_session, Session
import config
def _get_coordinator(request: Request) -> Coordinator:
# private helper function
# NOTE: You can pass the DIContainer in the same way
return request.app.state.coordinator
def user_provider(
session: Annotated[Session, Depends(get_session)], # 1
coordinator: Annotated[Coordinator, Depends(_get_coordinator)] # 2
) -> UserProvider: # 3
# UserProvider's lifecycle is bound to short endpoint's lifecycle, so it's safe to use strong references here
return UserProviderImpl( # 4
repository=UserRepository(session), # 5
mail_provider=MailProvider(config.mail_token), # 6
output=coordinator, # 7
on_user_created=coordinator.on_user_created # 8
# on_user_created: lambda: coordinator.on_user_created() # add a lambda if the method's signature is not compatible
)
Getting a database session through FastAPI's dependency injection system, ensuring that each request has a clean session.
Obtaining an instance of
Coordinatorfrom the application state, which is responsible for managing broader application-level tasks and acting as an event manager.Note: the function returns protocol but not the exact implementation
Constructing an instance of
UserProviderImplby injecting all the necessary dependencies. This demonstrates a practical application of dependency injection to assemble complex objects.Initializing
UserRepositorywith the session obtained from FastAPI's DI system. This repository handles all data persistence operations, abstracting the database interactions from the provider.Setting up
MailProviderusing a configuration token.Injecting
Coordinatoras the output protocol. This assumes thatCoordinatorimplements theUserProviderOutputprotocol, allowing it to receive notifications when a user is created.Assigns a method from
Coordinatoras a callback to be executed upon user creation. This allows for additional operations or notifications to be triggered as a side effect of the user creation process.
This structured approach ensures that the UserProvider is equipped with all necessary tools to perform its tasks effectively, while adhering to the principles of loose coupling and high cohesion.
Coordinator
The Coordinator class acts as the main orchestrator within your application, managing various services, interactions, events, setting the initial state, and injecting dependencies. Here's a detailed breakdown of its roles and functionalities based on the provided code:
# coordinator.py
from threading import Thread
import weakref
import uvicorn
import config
from services.api_service import get_app as get_fastapi_app
from entities.user import UserCreate
from repository.user_repository import UserRepository
from providers.mail_provider import MailProvider
from providers.user_provider import UserProvider, UserProviderImpl
from services.report_service import ReportService
from services.telegram_service import TelegramService
class Coordinator:
def __init__(self):
self.users_count = 0 # 1
self.telegram_service = TelegramService( # 2
token=config.telegram_token,
get_user_provider=lambda session: UserProviderImpl(
repository=UserRepository(session),
mail_provider=MailProvider(config.mail_token),
output=self,
on_user_created=self.on_user_created
)
)
self.report_service = ReportService(
get_users_count = lambda: self.users_count # 3
)
# Coordinator's Interface
def setup_initial_state(self):
fastapi_app = get_fastapi_app()
fastapi_app.state.coordinator = self # 4
# 5
fastapi_thread = Thread(target=lambda: uvicorn.run(fastapi_app))
fastapi_thread.start()
# 6
self.report_service.start()
self.telegram_service.start()
# UserProviderOutput Protocol Implementation
def user_provider_created_user(self, provider: UserProvider, user: UserCreate):
self.on_user_created(user)
# Event handlers
def on_user_created(self, user):
print("User created: ", user)
self.users_count += 1
# 7
if self.users_count >= 10_000:
self.report_service.interval_seconds *= 10
elif self.users_count >= 10_000_000:
self.report_service.stop() # 8
Some state can be shared between different providers, services, layers, and the entire app
Assembling implementations and injecting dependencies
Be aware of circular references, deadlocks, and memory leaks here, see the full code for detatils
Pass the coordinator instance to the FastAPI app state so you can access it in the endpoints via FastAPI's DI system
Start all services in separate threads
Already runs in a separate thread inside the service
Some cross-service logic here, just for example
Example of controlling services from the coordinator
This orchestrator centralizes control and communication between different components, enhancing manageability and scalability of the application. It effectively coordinates actions across services, ensuring that the application responds appropriately to state changes and user interactions. This design pattern is crucial for maintaining a clean separation of concerns and enabling more robust and flexible application behavior.
DI Container
However, in large-scale applications manual DI can lead to a significant amount of boilerplate code. This is when DI Container comes to rescue. DI Containers, or Dependency Injection Containers, are powerful tools used in software development to manage dependencies within an application. They serve as a central location where objects and their dependencies are registered and managed. When an object requires a dependency, the DI Container automatically handles the instantiation and provision of these dependencies, ensuring that objects receive all the necessary components to function effectively. This approach promotes loose coupling, enhances testability, and improves the overall maintainability of the codebase by abstracting the complex logic of dependency management away from the business logic of the application. DI Containers simplify the development process by automating and centralizing the configuration of component dependencies.
For python, there are many libraries providing different DI Container implementations, I looked almost all of them and wrote down the best IMO
python-dependency-injector — automated, class-based, has different lifecycle options like Singleton or Factory
lagom — a dictionary interface with automatic resolve
dishka — good scope control via context manager
that-depends — support for context managers (objects required to be closed in the end), native fastapi integration
punq — more classic approach with
registerandresolvemethodsrodi — classic, simple, automatic
main.py
For the end, let's update the main.py file:
# main.py
from coordinator import Coordinator
def run(): # entry point, no logic here, only run the coordinator
coordinator = Coordinator()
coordinator.setup_initial_state()
if __name__ == '__main__':
run()
Conclusion
To gain a comprehensive understanding of the architectural and implementation strategies discussed, it is beneficial to review all files in the repository. Despite the limited amount of code, each file is enriched with insightful comments and additional details that offer a deeper understanding of the application’s structure and functionality. Exploring these aspects will enhance your familiarity with the system, ensuring you are well-equipped to adapt or expand the application effectively.
This approach is universally beneficial across various Python applications. It's effective for stateless backend servers such as those built with FastAPI, but its advantages are particularly pronounced in no-framework apps and applications that manage state. This includes desktop applications (both GUI and command-line), as well as systems that control physical devices like IoT devices, robotics, drones, and other hardware-centric technologies.
Additionally, I highly recommend reading Clean Code by Robert Martin for further enrichment. You can find a summary and key takeaways here. This resource will provide you with foundational principles and practices that are crucial for maintaining high standards in software development.


